Eyes OCR support
Introduction
Eyes supports OCR (optical character recognition)-based functionality by combining page capture capabilities with OCR intelligence, which together provide a solution for two use cases:
-
Extract the visible text of a given region in an application page.
-
Find the location of some given text on the application page.
This feature is experimental. Please note that the functionality and/or API may change.
Using OCR to extract the text on an application page provides you with advantages over other techniques, such as directly examining the contents of a DOM text field:
-
The text can appear in an image and not just as character data.
-
You can ensure that you only find text that is visible to the user.
-
Eyes can find the text wherever it appears on the page without requiring a specific locator to a specific element.
The sections that follow describe two Eyes methods that provide you with OCR capabilities, and these are followed by some details that are common to both of these methods. The article concludes with a full example you can build on.
Extracting text from a defined region
The Eyes.extractText method allows you to search an application window for the occurrence of text. This method is based on OCR, so strings may originate from text elements, images, or any other source. You can specify the area to be searched by supplying a CSS locator, a DOM element, or a rectangular area. The search area may be in any part of the application window (not only the viewport) but not within a sub-frame.
The following snippet illustrates the different ways that the region to be searched can be specified:
The Eyes.extractText method takes as a parameter a target configuration object. The target configuration object consists of a definition of the target and an optional hint.
- target
- As shown in the example snippet, this can be a Selenium element, the definition of a rectangular region on the page, or a CSS locator that specifies an ID or a tag. These can point to any position on the page except for inside an inner frame.
- hint
-
The hint is a string that can be used to provide some context. The OCR uses the hint to disambiguate the text it finds, for example, to differentiate between letters and digits that are similar:
-
O (letter after N) and 0 (zero)
-
l (lower case L) and 1 (one)
-
S (letter before T) and 5 (five),
-
Z (last letter) and 2 (two)
For more information on what can be provided as a hint, see section Patterns and Hints below.
-
The return value is an array of strings, one per target, in the configuration object. If no text is found then the array element for that target is an empty string. If the OCR finds multiple lines of text (text with different vertical offsets), then it returns them in a single string, in left-right-top-bottom order, separated by newline (\n) characters.
Finding the position of specific text
The Eyes.extractTextRegions method allows you to ask Eyes to search the application window and retrieve the locations that contain given literal text, or a pattern. This method is based on OCR, so strings may originate from text fields, images, or any other source.
You can specify the text you are looking for by either providing literal text or a regular expression like pattern. See the Patterns and Hints section below for a full description of the possible values for the pattern. In the current implementation, the search region is implicitly the current browser viewport (what you see when you load a URL in the browser without scrolling).
The example below illustrates finding the position of any text using a wild card, providing full or partial literal text, and a more sophisticated wild card.
The returned object is a map consisting of key/value pairs, where the keys are the patterns specified in the patterns array passed as a parameter, and each value is an array of matched lines for that pattern.
Each matched line is represented as an object that consists of the following properties:
- text:
- A string that is the text that was found.
- x, y:
- The top right corner of the text's bounding rectangle in the captured image.
- width, height:
- The dimensions of the text's bounding rectangle.
Only patterns that matched are returned. If no text is found, then an empty object is returned (an object without any properties).
The Eyes.extractTextRegions method matches single lines of text. If multiple lines match the pattern, then the pattern key value array contains each line as a separate element. Note that this behavior is different to the extractText method described, which returns multiple lines as a single string with \n indicating where a line break was detected.
The TextRegionSettings configuration object that is passed as a parameter to extractTextRegion takes an array of patterns and optional properties described below:
- patterns
-
Patterns are defined as an array of strings. These serve two purposes:
-
To define the pattern you are looking for – only lines that contain a substring that matches the pattern will be returned.
-
To define expectations to the OCR – to enable it, for example, to disambiguate alphabetic and numeric characters such as:
-
O (letter after N) and 0 (zero)
-
l (lower case L) and 1 (one)
-
S (letter before T) and 5 (five)
-
Z (last letter) and 2 (two)
-
-
- ignoreCase
-
If this property is defined, and has a value of false, then the case of the text in the pattern must match the case of the corresponding character in the image text. If it has a value of true, then a lowercase or uppercase literal in the pattern will match either case in the image text. Since the pattern also serves as a hint, when ignoreCase is set to false, the OCR result will use the pattern case to disambiguate lowercase and uppercase characters that are similar (such as lowercase and uppercase S and Z). This is an optional property, with a default value of true.
- firstOnly
-
If this property is defined and has a value of true, then only the first match found for each pattern is returned. If it has a value of false, then all of the matches that are found are returned for each pattern. This is an optional property, with a default value of false.
Patterns and Hints
Both the Eyes.extractText and the Eyes.extractTextRegions methods support specifying parameter (hint and pattern respectively) that can be a combination of literal characters and regular expression like character classes and quantifiers. The form this parameter can take is the same for both methods, but they have different roles.
This section describes the legal syntax of the hint/pattern parameter. For a description of how the parameter is used, see the detailed description of each method above.
An OCR pattern/hint may be composed of any of the following characters:
| . | Matches any character. |
| \d | Matches any digit 0-9. |
| \l | (Lowercase L) Matches any letter a-z or A-Z. |
| \w | Matches any word character a-z, A-Z, or _. |
| \S | Matches any non-space character. |
| + | Repeats the previous literal character or character class one or more times, for example, "\d+" is any multi-numeral digit and "\w+" is any word that contains only letters or an underscore. This pattern cannot cross a line break. |
| \ | Escapes a character that has a special meaning – specifically use this to specify the literals "\", ".", and "+" by using " \\", "\", and "\+". |
| space | The OCR is tolerant of spaces between characters, so you don’t have to add them to the pattern. Where a space is detected in the image, it is translated into a single space. If you add an explicit space in the pattern, then it matches any number of spaces. |
| Any other character represents itself. | |
Depending on the programming language you use, the back-slashed character classes may need to be specially encoded in the string, for example, by using a double back-slash such as "\\w".
Example patterns
-
"\w+": Match a word
-
"\d+": Match a number
-
"\S+" : Match mixed alphabetic and digital data
-
"\d+/\d+/\d+": Match a date, such as 01/04/1972
-
"$\d+.\d+": Match an amount of money, such as $150.00
Full example
The code below is a fully functional example that uses the methods described in this article.
The test runs on the following application:
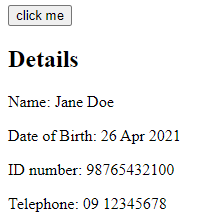
You can see the HTML of this application here.